Aprendizaje por refuerzo cuántico
ConceptoSobre
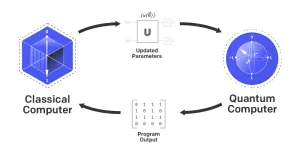
El Aprendizaje por Refuerzo Cuántico (QRL) combina principios de la computación cuántica y el aprendizaje por refuerzo para optimizar la toma de decisiones en entornos complejos. Aprovecha propiedades cuánticas como la superposición y el paralelismo para representar estados y acciones de forma más eficiente. En QRL, los pares tradicionales de estado-acción se representan como estados cuánticos, lo que permite la exploración simultánea de múltiples posibilidades. Este enfoque puede mejorar la velocidad de aprendizaje y equilibrar la exploración y la explotación, aspectos cruciales en escenarios de aprendizaje por refuerzo. El QRL tiene aplicaciones potenciales en la optimización de políticas para sistemas autónomos, como vehículos autónomos y drones. Puede gestionar escenarios complejos con mayor eficiencia que los métodos clásicos, especialmente en entornos dinámicos donde interactúan múltiples agentes. A pesar de las limitaciones actuales del hardware cuántico, el QRL ofrece avances prometedores en el aprendizaje automático al integrar algoritmos cuánticos con técnicas de computación clásica. Este enfoque híbrido puede mejorar la eficiencia computacional y la capacidad de toma de decisiones en aplicaciones del mundo real.